
Groq’s LPU Chip Technology: On-Chip SRAM
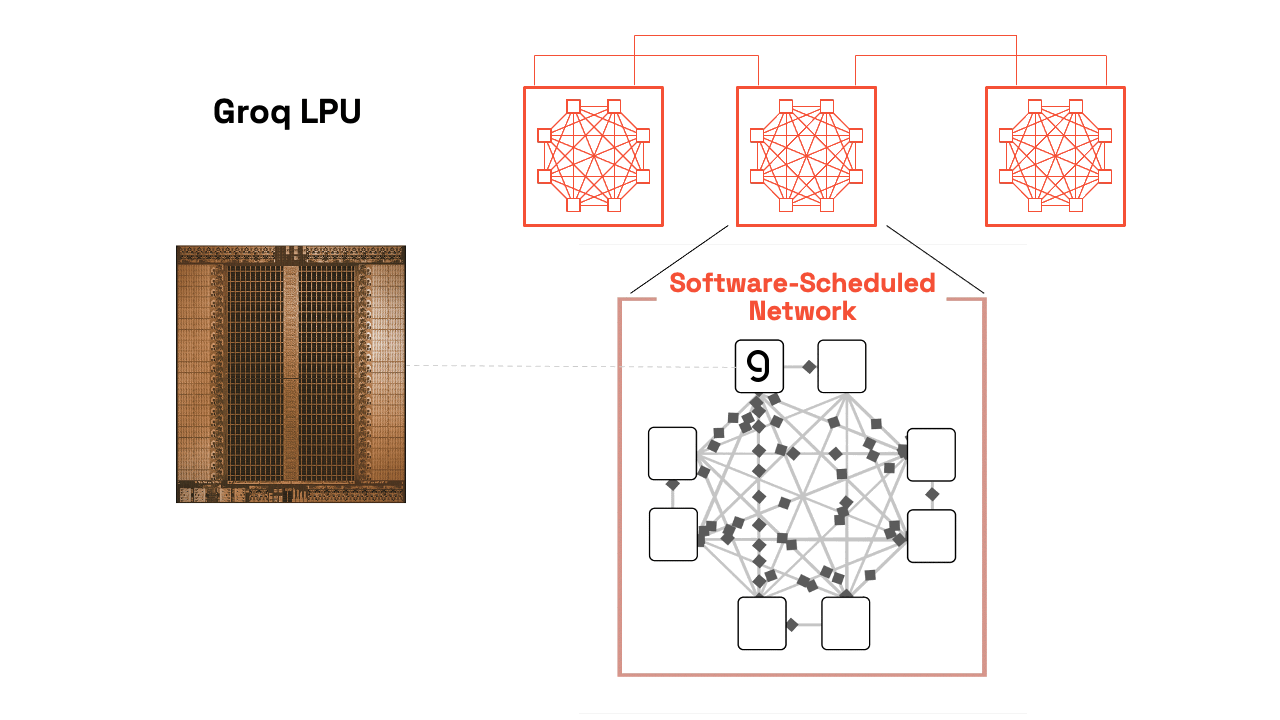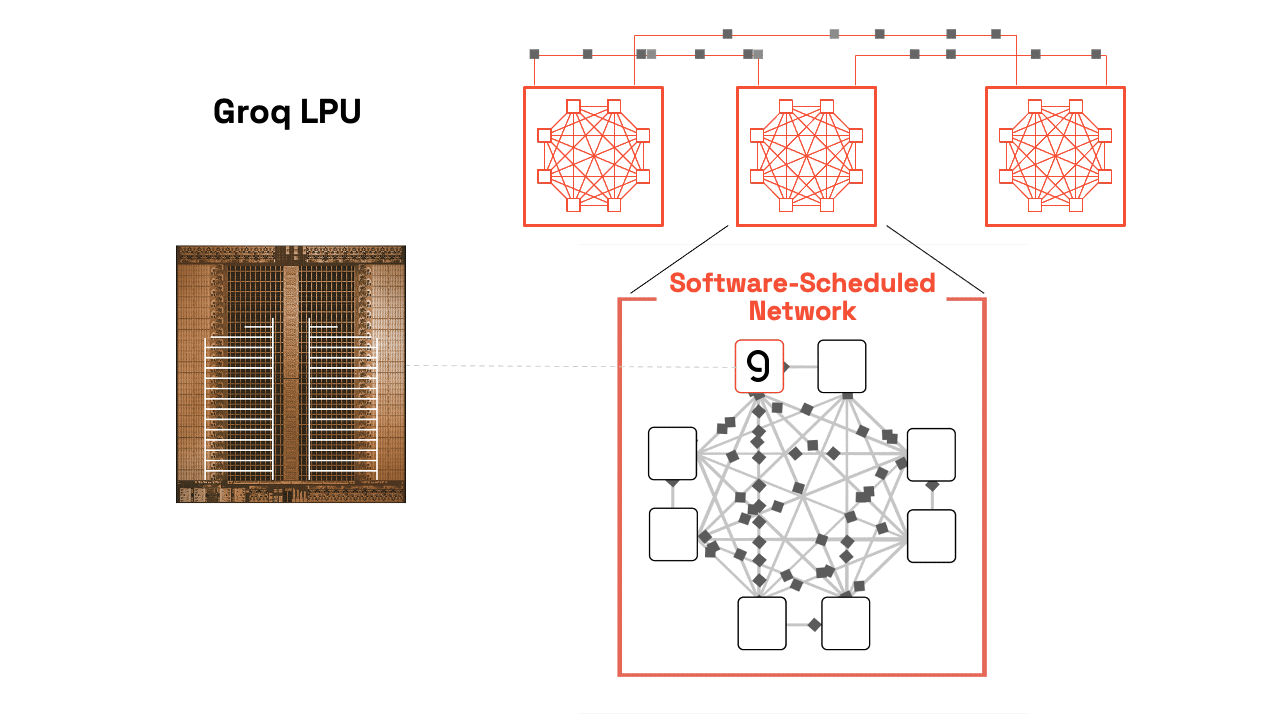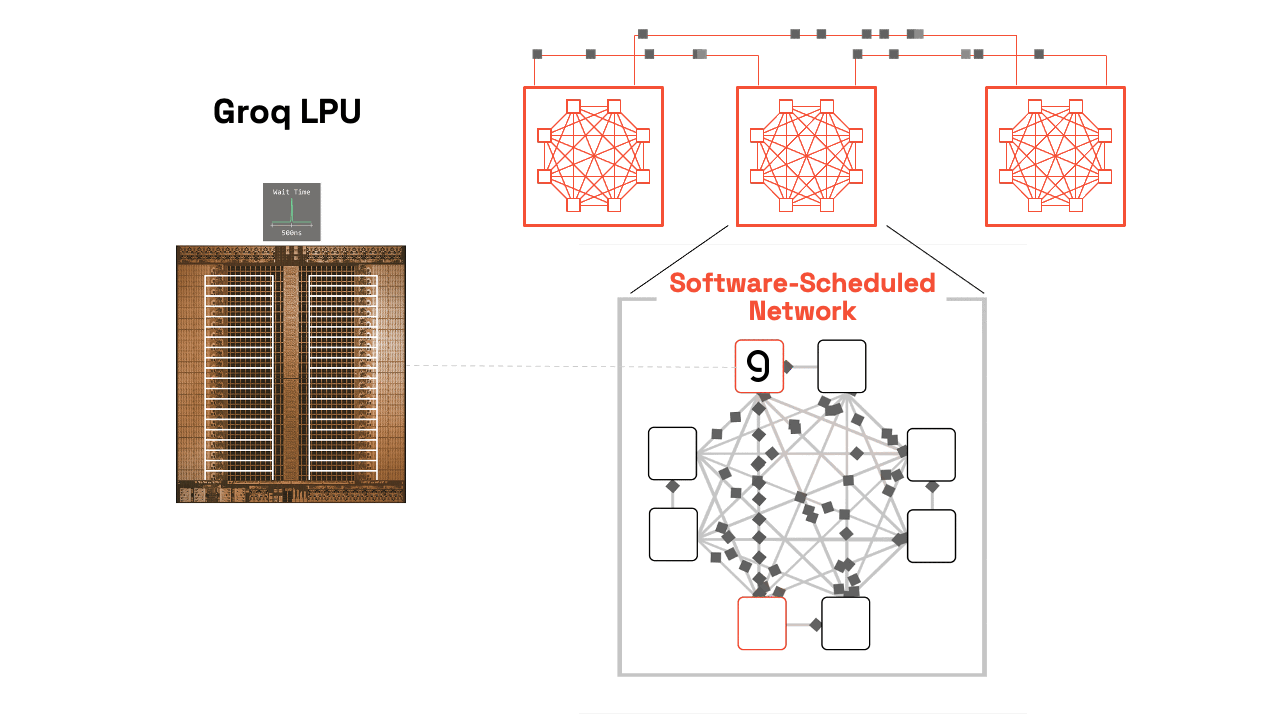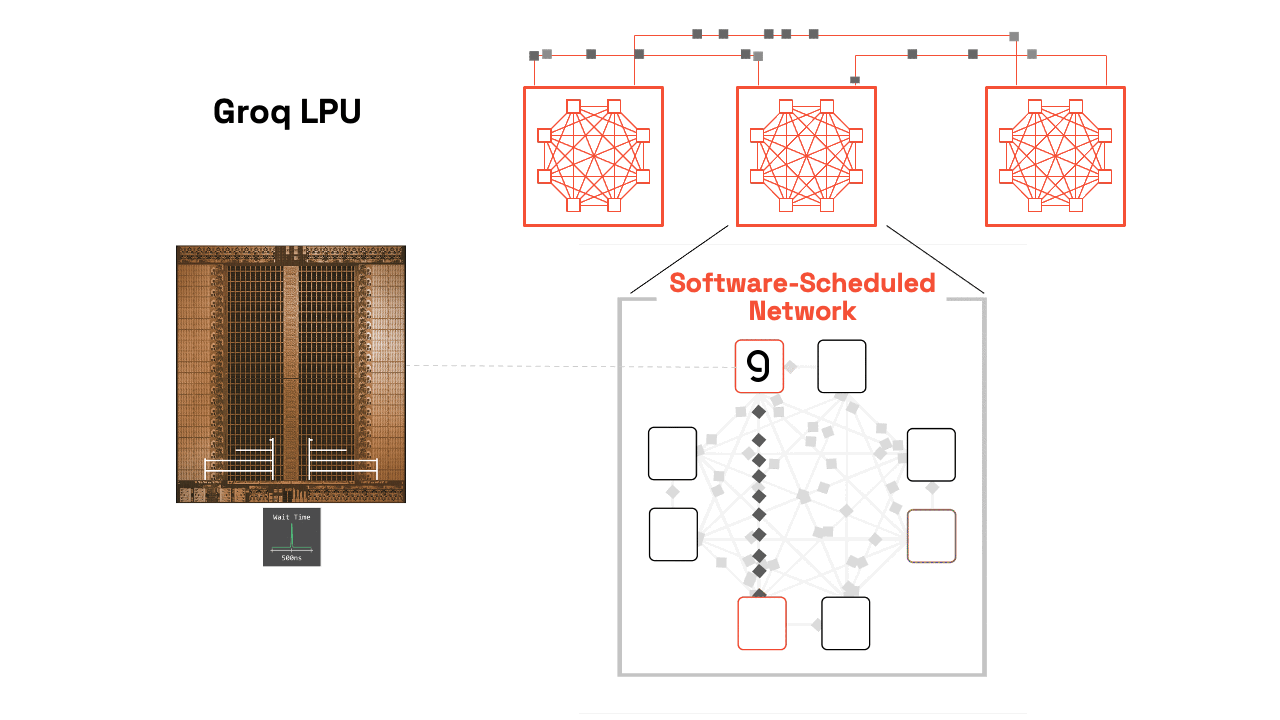
Groq chip technology, specifically the Language Processing Unit (LPU), is an architecture designed specifically to solve the “memory bottleneck” that slows down AI models on traditional chips like GPUs [1.2, 2.1]. Founded by former architects of Google’s TPU, Groq has shifted from a startup to a major industry player, famously resulting in a $20 billion acquisition/licensing deal with Nvidia in late 2025 [3.2].
The core of Groq’s success lies in three pillars: Deterministic Architecture, On-chip SRAM, and a Software-First design [2.1, 4.2].
1. Deterministic “Clockwork” Execution
Standard GPUs use dynamic scheduling, where the chip decides in real-time which task to prioritize. This creates “jitter”—random delays that make AI responses feel uneven [6.1].
- Zero Variance: Groq removed all hardware-side “decision makers” (like branch predictors or cache controllers) [1.2, 4.2].
- Predictability: The hardware does exactly what the software tells it to do, down to the exact clock cycle. If a calculation is scheduled to take 400 cycles, it takes exactly 400 cycles every single time [1.2, 6.1].
- Synchronous Networking: Using a “Plesiosynchronous” system, hundreds of Groq chips can be synchronized to act as one single, massive processor [1.2, 4.3].
2. The SRAM Memory Advantage
Instead of using external High Bandwidth Memory (HBM) like Nvidia, which requires data to “travel” back and forth, Groq uses SRAM (Static Random-Access Memory) built directly onto the chip [7.1, 7.3].
- Speed: Groq’s on-chip SRAM provides a bandwidth of roughly 80 TB/s, compared to only 3.35 TB/s on an Nvidia H100 [2.1, 7.3].
- Capacity Trade-off: SRAM is fast but physically large. One Groq chip only holds 230 MB of data [2.3, 7.3].
- Scaling: To run a model like Llama 3 70B (which needs ~140 GB), Groq links together a rack of approximately 576 chips [1.2, 7.2].
3. Tiled Architecture & Data Streams
The chip is organized into a “Tiled” or “Functional Slice” layout [4.1].
- Vertical Slices: The chip is divided into specialized columns: Memory (MEM), Vector math (VXM), and Matrix math (MXM) [4.1].
- Horizontal Streams: Data flows across these slices on “conveyor belts” [2.1].
- Matrix Multiplication: The Matrix Execution Modules (MXM) can perform a 320-element fused dot-product in just 20 cycles, making it incredibly efficient for the linear algebra required by AI [4.1, 2.3].
4. Software-First (The Compiler is Captain)
In Groq’s world, the compiler does all the hard work that hardware usually handles [2.1, 4.2].
- Spatial Orchestration: The compiler maps the AI model’s data flow across the physical geometry of the chip before the program even runs [1.2, 4.2].
- Resource Management: It manages all memory and data movement, ensuring that when a math unit is ready for a number, that number arrives at that exact nanosecond [4.1, 6.1].
Comparison of Performance (2025/2026 Benchmarks)
| Metric | Nvidia H100 (GPU) | Groq LPU |
| Throughput (Llama 3 8B) | ~100–150 tokens/sec | 877 tokens/sec [3.2] |
| Throughput (Llama 3 70B) | ~30–50 tokens/sec | 240–300 tokens/sec [5.1, 5.2] |
| Memory Bandwidth | 3.35 TB/s | ~80 TB/s [7.3] |
| Best For | Training & Batch Inference | Real-time, Low-latency Inference [3.2, 6.1] |
References
- [1.2] HackerNoon (2025), “Groq’s Deterministic Architecture is Rewriting the Physics of AI Inference.”
- [2.1] Groq Official (2025), “What is a Language Processing Unit?”
- [2.3] TechPowerUp (2024), “Groq LPU AI Inference Chip is Rivaling Major Players.”
- [3.2] IntuitionLabs (2025), “Nvidia’s $20B Groq Deal: Strategy, LPU Tech & Antitrust.”
- [4.1] Groq Whitepaper (2020), “Groq Rocks Neural Networks: Tensor Streaming Processor.”
- [4.2] Medium (2025), “The Compiler is the Captain: Software-Defined Hardware.”
- [5.1] ArtificialAnalysis.ai (2024), “LLM Benchmark: Groq LPU Performance Results.”
- [6.1] 601MEDIA (2025), “How Groq LPU Works: A Comparison with GPU and TPU.”
- [7.3] Bojie Li (2024), “Groq Inference Chips: A Trick of Trading Space for Time.”